Selenium获取网页源码
写在前面
Python+Selenium可以做网络爬虫。所以,我们可以从网页源码中爬出想要的信息。
Selenium的page_source方法可以获取到页面源码。获取到源码以后可以再查找自己想要的信息。
源码保存
为了方便查看网页源码,我们可以借用python提供的方法,将获取到的网页源码写入到html文件中。
#get_source.py
#www.testclass.cn
#Altumn
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.testclass.cn/")
driver.maximize_window()
driver.implicitly_wait(10)
page = driver.page_source
#打印源码,防止乱码加上编码格式;
print(page.encode("utf8"))
#保存网页源码名称为:testclass_cn.html,存储路径为工程根目录;
f=open('./testclass_cn.html',mode="w",encoding="utf-8")
f.write(page)
存储的网页效果(局部截图):
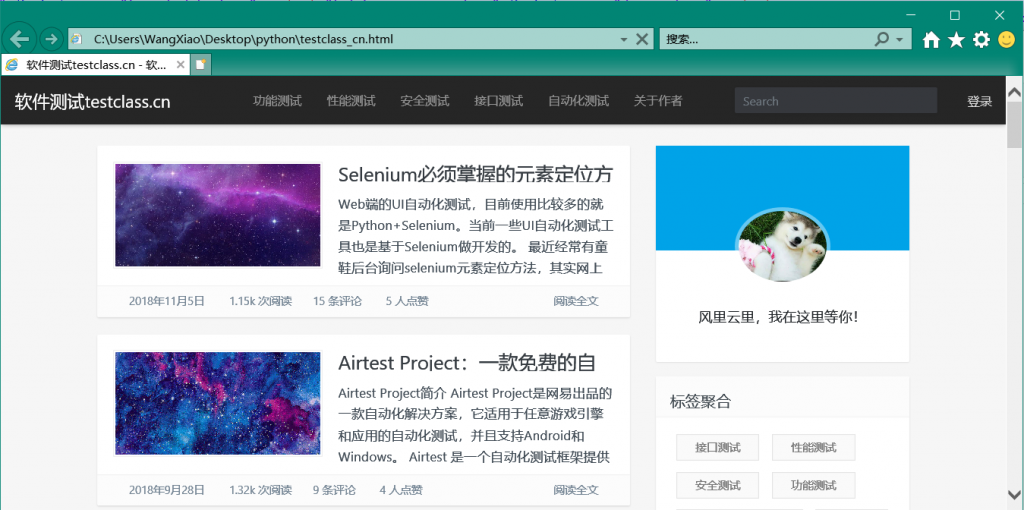
源码操作
成功获取源码以后,我们可以在源码中继续查找想要的信息。
例如,我想要获取该页面上所有关于‘.html’链接的信息。或者我们把抓取的URL集保存到本地文档中。
#get_source.py
#www.testclass.cn
#Altumn
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.get("https://www.testclass.cn/")
driver.maximize_window()
driver.implicitly_wait(10)
page = driver.page_source
#用正则表达式匹配URL集;
url_list = re.findall('href=\"(.*?)\"', page, re.S)
#打印出含有".html"的URL集
for url in url_list:
if ".html" in url:
print(url)
#存储获取到的URL到data.txt;
with open('data.txt','w') as f:
for url in url_list:
f.write(url + '\n')
温馨提示:欢迎加入软件测试学习交流QQ群:670250199
作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
文章评论(2)
学到啦
小程序评论测试---该条评论来自微信小程序。😊